Published on 2025-06-28T04:57:07Z
What is Classification in Analytics? Examples of Classification
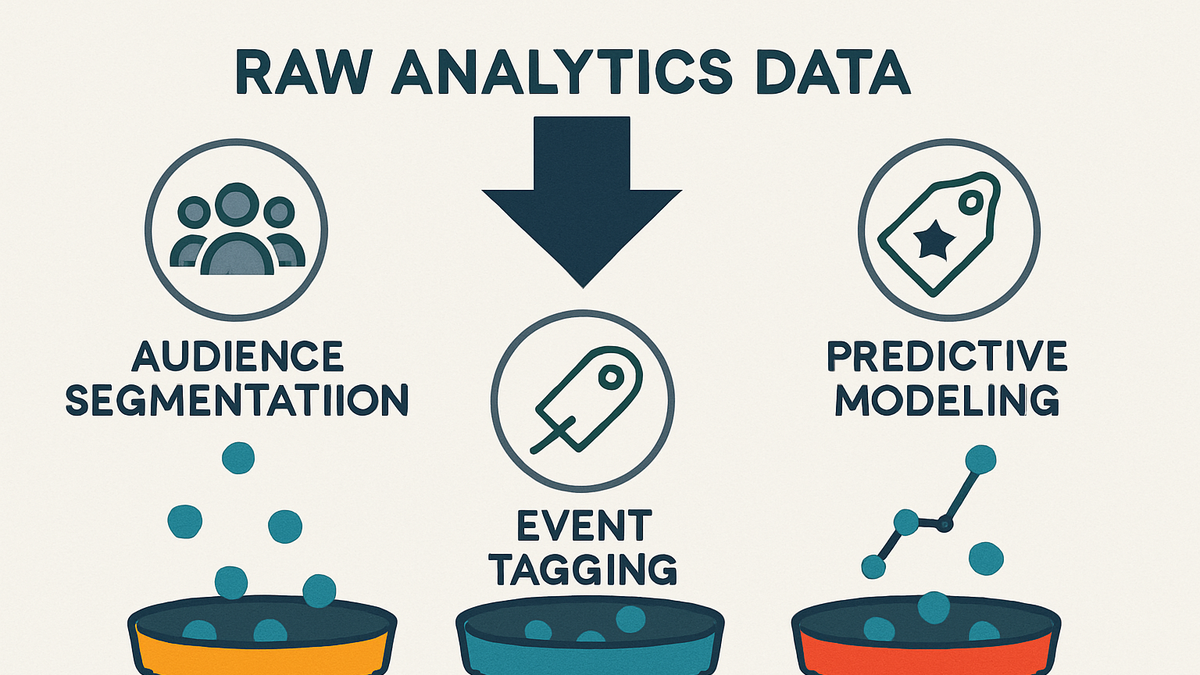
Classification in analytics refers to the process of organizing raw data into predefined categories or labels for easier reporting and analysis. By assigning data points—such as user interactions, events, or transactions—to discrete groups, analysts can quickly identify patterns and trends. Classification can be performed manually, through rule-based systems, or by leveraging machine-learning algorithms. This process lays the groundwork for advanced analytics tasks like predictive modeling and audience segmentation. Whether using a privacy-focused tool like PlainSignal or a full-featured platform like GA4, classification helps turn unstructured metrics into actionable insights. Clear classification schemes improve data consistency, support automated reporting, and enhance decision-making across marketing, product, and business intelligence teams.
Classification
Classification in analytics is categorizing data into discrete groups for reporting, segmentation, and predictive modeling.
Introduction to Classification
Classification organizes data into meaningful groups to simplify analysis, reporting, and decision-making.
-
Purpose of classification
Classification assigns labels or categories to data points, making complex datasets easier to interpret.
-
Key benefits
Implementing classification offers several advantages in analytics:
-
Enhanced segmentation
Breaks down audiences or events into targeted groups for deeper insights.
-
Improved reporting
Simplifies dashboards by summarizing data into well-defined categories.
-
Predictive modeling
Serves as a foundation for machine-learning algorithms to forecast outcomes.
-
Types of Classification
There are multiple approaches to classification in analytics, each suited to different use cases and data volumes.
-
Manual classification
Data is labeled by humans, often through tagging or categorizing events and pages.
-
Rule-based classification
Uses predefined rules or patterns to automatically assign categories.
-
Example
Routing URLs containing
/blog/to the “Blog Posts” category via simple regex.
-
-
Machine learning classification
Applies algorithms to learn from historical data and categorize new records.
-
Common algorithms
Decision trees, logistic regression, and random forests are often used.
-
Implementing Classification in PlainSignal and GA4
Modern analytics platforms offer built-in ways to classify data. Below are examples for PlainSignal and Google Analytics 4.
-
PlainSignal (cookie-free simple analytics)
PlainSignal focuses on privacy-first analytics. You can classify pages or events by adding custom parameters to your tracking code.
-
Tracking code integration
Use the following snippet to track and classify pages or events:
<link rel="preconnect" href="//eu.plainsignal.com/" crossorigin /> <script defer data-do="yourwebsitedomain.com" data-id="0GQV1xmtzQQ" data-api="//eu.plainsignal.com" src="//cdn.plainsignal.com/plainsignal-min.js"></script>You can then add a
data-classification="category_name"attribute to your HTML elements to group them.
-
-
Google analytics 4 (GA4)
GA4 provides classification through custom dimensions, event parameters, and audience definitions.
-
Event parameter configuration
In your gtag code, include parameters to classify events. For example:
gtag('event', 'purchase', { 'value': 99.99, 'currency': 'USD', 'item_category': 'electronics' }); -
Audience & exploration reports
Use your custom
item_categorydimension in the Analysis Hub to segment and analyze users by category.
-
Best Practices & Challenges
Effective classification requires planning, governance, and ongoing maintenance to stay accurate and relevant.
-
Best practices
Establish clear rules and processes to keep classifications consistent and scalable.
-
Clear naming conventions
Use descriptive, standardized names for each category.
-
Documentation
Maintain a data dictionary that outlines classification logic and definitions.
-
Regular audits
Periodically review and update categories to reflect evolving data and business needs.
-
-
Common challenges
Be aware of pitfalls that can undermine classification accuracy.
-
Ambiguous categories
Overlapping or poorly defined categories can lead to inconsistent labeling.
-
Scalability issues
Rule-based systems may become unwieldy as the number of categories grows.
-
Data drift
Changing user behaviors may require frequent updates to classification rules.
-