Published on 2025-06-28T09:13:28Z
What is Data Stitching? Analytics Examples with GA4 & PlainSignal
Data stitching refers to the process of merging visitor data points across sessions, devices, and channels to construct a unified view of user behavior. It uses identity resolution techniques, deterministic and probabilistic matching algorithms, or unique identifiers to match records accurately. In traditional cookie-based systems, stitching often relies on third-party cookies, but modern privacy regulations and browser restrictions have led to cookie-free approaches like PlainSignal’s simple analytics. Data stitching is crucial in platforms like Google Analytics 4 (GA4), which employs user_id and Google Signals to link sessions across devices. By stitching data, analysts can measure cross-device user journeys, improve attribution accuracy, and derive deeper insights into engagement and retention. This article explores the core concepts, benefits, challenges, and practical examples of data stitching using GA4 and PlainSignal.
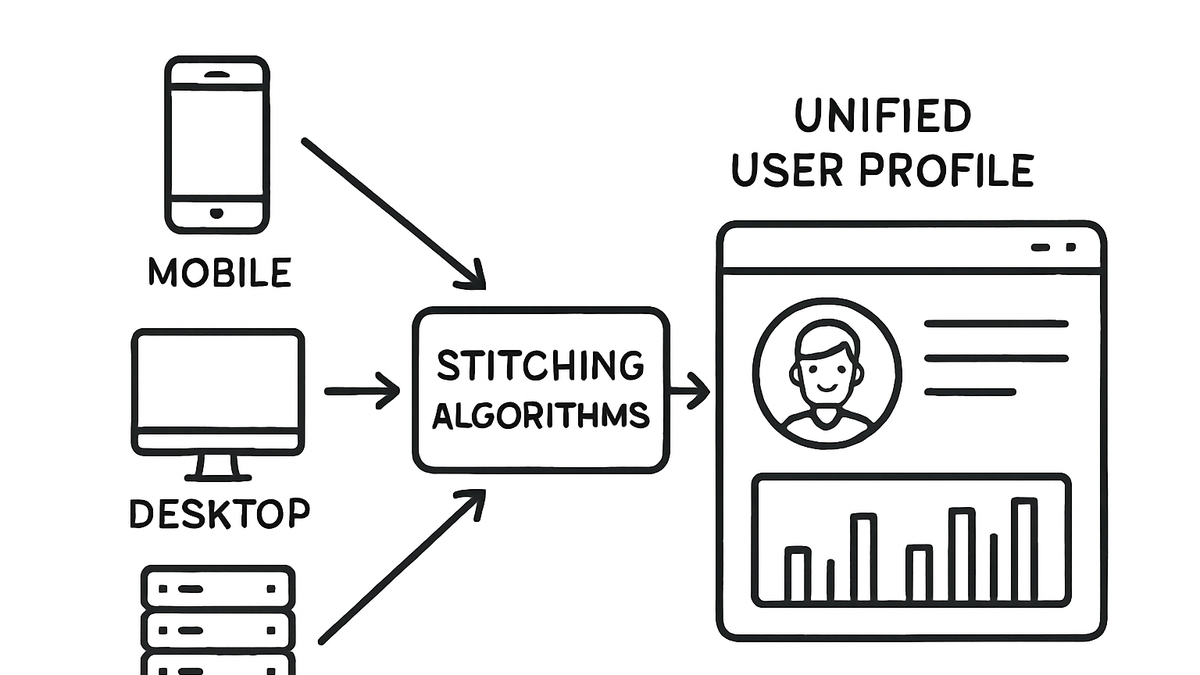
Data stitching
Merging user data across sessions and devices to create a unified analytics view for better attribution, insights, and personalization.
Why Data Stitching Matters in Analytics
Data stitching plays a pivotal role in modern analytics by connecting fragmented data points into coherent user stories. Without stitching, analysts see isolated sessions that mask the true customer journey. By merging data across touchpoints, organizations can gain comprehensive insights into user behavior, optimize marketing decisions, and improve personalization strategies.
-
Enhanced user insights
By connecting data points across sessions and devices, data stitching provides a holistic view of user behavior, revealing patterns that single-session analytics miss.
-
Accurate attribution
Unified user data allows marketers to attribute conversions and engagement to the correct channels and campaigns, improving budget allocation and ROI analysis.
Core Components and Techniques of Data Stitching
Effective data stitching relies on several key components and methodologies that ensure accurate and reliable user matching across diverse data sources.
-
Identity resolution
The process of matching user identifiers—such as user_id, hashed email addresses, or device fingerprints—to link disparate records belonging to the same individual.
-
Deterministic matching
Uses explicit identifiers like login credentials or hashed emails to match user records with high accuracy.
-
Probabilistic matching
Applies statistical algorithms and behavioral signals (e.g., IP address, browser fingerprint) to infer matches with confidence scores.
-
-
Sessionization
Grouping events into sessions based on factors like inactivity timeouts, referrer changes, or navigation patterns to define coherent user visits.
-
Time-based sessionization
Defines a session cutoff after a period of inactivity (commonly 30 minutes) to separate distinct visits.
-
Referrer-based sessionization
Starts a new session when the traffic source or attribution context changes, such as a new campaign or medium.
-
-
Event consolidation
Normalizing and merging events from various platforms or SDKs into a unified schema to facilitate consistent stitching and analysis.
-
Schema standardization
Aligns different event payloads to a common format with consistent fields like timestamp, event name, and user identifier.
-
Timestamp normalization
Converts event timestamps from multiple time zones and formats into a single standardized convention.
-
Implementing Data Stitching with SaaS Tools
Practical demonstrations of how leading analytics platforms handle data stitching, including both cookie-free and user-based approaches.
-
PlainSignal example
PlainSignal provides a privacy-centric, cookie-free analytics solution that stitches events using domain-based identifiers and hashed signatures.
-
Tracking code integration
Add the following code to your HTML to enable PlainSignal stitching:
<link rel="preconnect" href="//eu.plainsignal.com/" crossorigin /> <script defer data-do="yourwebsitedomain.com" data-id="0GQV1xmtzQQ" data-api="//eu.plainsignal.com" src="//cdn.plainsignal.com/plainsignal-min.js"></script>
-
-
Google analytics 4 example
GA4 leverages user_id, Google Signals, and gtag.js to stitch user interactions across devices when properly configured.
-
Gtag.js setup
Include the GA4 snippet with your measurement ID:
<script async src="https://www.googletagmanager.com/gtag/js?id=G-XXXXXXX"></script> <script> window.dataLayer = window.dataLayer || []; function gtag(){dataLayer.push(arguments);} gtag('js', new Date()); gtag('config', 'G-XXXXXXX', { 'send_page_view': true }); </script> -
Enabling user id
Configure the user_id parameter to unify sessions across devices:
gtag('config', 'G-XXXXXXX', { 'user_id': USER_ID });
-
Challenges and Best Practices
Navigating privacy, technical, and operational hurdles is essential to implement reliable and compliant data stitching.
-
Privacy and compliance
Ensure data stitching respects user consent frameworks and regional regulations such as GDPR, CCPA, and ePrivacy.
-
Consent management
Implement a consent management platform (CMP) to capture and honor user preferences before stitching any personal data.
-
Data anonymization
Use hashing, pseudonymization, or tokenization to minimize the risk of exposing personal identifiers.
-
-
Data quality management
Maintain accuracy by monitoring for duplicates, lost events, and mismatched records in stitched datasets.
-
Duplicate detection
Identify and merge or discard identical records to prevent inflated metrics.
-
Regular audits
Compare stitched results against raw logs or backup systems to validate matching logic.
-
-
Scalability and performance
Design stitching workflows to handle high event volumes with low latency using distributed processing and optimized storage.
-
Batch vs. real-time processing
Choose between periodic batch stitching and streaming approaches based on latency requirements and system capacity.
-
Infrastructure optimization
Leverage cloud-based platforms, efficient indexing, and auto-scaling to sustain performance under peak loads.
-