Published on 2025-06-26T04:39:15Z
What is a Classification Model in Analytics? Examples with PlainSignal and GA4
A classification model is a type of supervised machine learning algorithm used in analytics to predict categorical outcomes based on historical data. These models categorize data points – such as users or sessions – into discrete classes like ‘churn’ vs. ‘retained’ or ‘fraudulent’ vs. ‘legitimate.’ In digital analytics, classification models power use cases like user segmentation, churn prediction, and fraud detection by learning patterns from past behavior. Builders can train classification models using data collected from analytics platforms like PlainSignal or Google Analytics 4 (GA4), leveraging event-level tracking or GA4’s built-in predictive metrics. Once deployed, these models help marketers and analysts make data-driven decisions by accurately classifying future user behavior. Key steps include data preparation, model training, evaluation using metrics like accuracy and ROC-AUC, and ongoing monitoring to maintain performance.
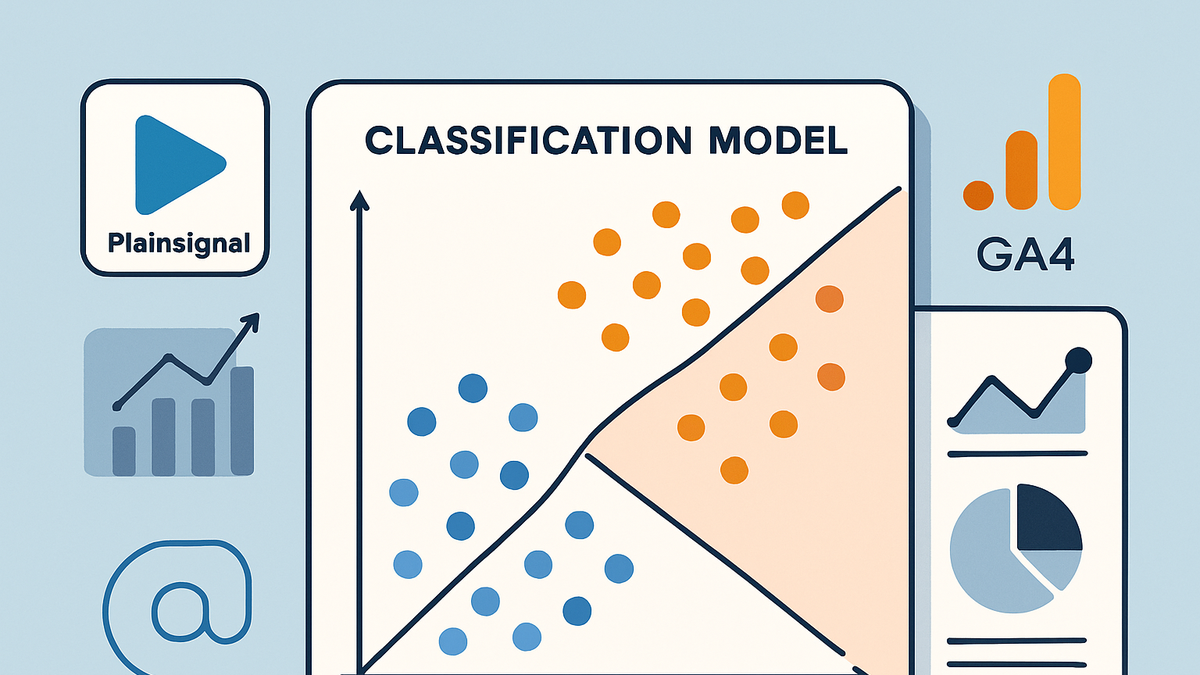
Classification model
Classification models in analytics predict categorical outcomes, powering use cases like user segmentation, churn prediction, and fraud detection.
Overview of Classification Models
This section introduces classification models, a type of supervised learning algorithm for categorizing data into discrete classes. They learn from labeled examples to predict outcomes such as user segments or churn probability. There are two main types of classification: binary and multiclass. In analytics, classification models help transform raw event data into actionable categories. Understanding the basics sets the foundation for advanced applications and evaluation.
-
Definition and purpose
A classification model assigns input data points to one of two or more classes based on patterns learned from historical data. It helps analysts predict outcomes like whether a user will convert or churn.
-
Types of classification models
Binary classification models predict one of two possible classes, while multiclass models handle three or more categories. Common algorithms include logistic regression, decision trees, random forests, and support vector machines.
-
Binary classification
Predicts one of two outcomes, such as ‘fraud’ vs. ‘legitimate’.
-
Multiclass classification
Predicts one of multiple classes, such as customer segments A, B, or C.
-
Applications in Analytics
Classification models translate raw analytics data into discrete insights for business decisions. They power scenarios like user segmentation, churn prediction, and fraud detection. By categorizing users, analysts can personalize experiences and allocate resources effectively. Each application leverages different labels and features derived from event data. Examples below illustrate typical uses in digital analytics.
-
User segmentation
Classifying users into segments based on behavior, demographics, or engagement levels to tailor marketing strategies.
-
Churn prediction
Predicting whether a customer is likely to stop using a service, enabling proactive retention campaigns.
-
Fraud detection
Identifying potentially fraudulent activity by labeling transactions or sessions as ‘fraudulent’ or ‘legitimate’.
Implementation with PlainSignal and GA4
This section explains how to collect data and train classification models using PlainSignal’s cookie-free analytics and GA4’s predictive features. It covers data collection, code integration, and leveraging built-in predictive metrics.
-
Using PlainSignal data for model training
Collect event-level data with PlainSignal’s cookie-free tracking script, then export the raw events to your data warehouse or ML pipeline for feature engineering and model training.
-
Tracking code snippet
<link rel="preconnect" href="//eu.plainsignal.com/" crossorigin /> <script defer data-do="yourwebsitedomain.com" data-id="0GQV1xmtzQQ" data-api="//eu.plainsignal.com" src="//cdn.plainsignal.com/plainsignal-min.js"></script> -
Data export
Export collected events as JSON or CSV to integrate with tools like Python, R, or BI platforms for feature extraction.
-
-
Leveraging GA4 predictive metrics
Google Analytics 4 offers built-in predictive metrics like purchase probability and churn probability. These predictions use Google’s trained classification models and can be applied to audiences for targeted campaigns.
-
Enabling predictive metrics
In GA4, navigate to Admin > Property > Predictive metrics to enable purchase and churn probability for your property.
-
Model Evaluation and Best Practices
Proper evaluation ensures your classification model is accurate and reliable. Focus on selecting appropriate metrics, validating with cross-validation, and monitoring drift. This section outlines the key evaluation techniques and best practices to follow.
-
Evaluation metrics
Use metrics like accuracy, precision, recall, F1-score, and ROC-AUC to measure classification performance. Choose metrics based on class balance and business objectives.
-
Best practices
Balance datasets to avoid bias, perform cross-validation, regularly retrain models with fresh data, and monitor performance over time. Ensure compliance with privacy regulations when handling user data.
Challenges and Considerations
Building and deploying classification models in analytics involves challenges such as data quality, user privacy, and bias. Understanding these considerations is critical to developing robust, ethical models.
-
Data quality and quantity
Insufficient or noisy data can degrade model performance. Ensure you have representative, labeled datasets and clean missing or inconsistent values.
-
Privacy and compliance
Respect user privacy by adhering to regulations like GDPR. With cookie-free analytics, ensure transparent data collection and provide opt-outs.
-
Bias and fairness
Monitor for bias in training data that can lead to unfair predictions. Use techniques like re-sampling or bias correction to mitigate issues.