Published on 2025-06-22T06:16:34Z
What is Supervised Learning? Examples and Applications in Analytics
Supervised learning is a subset of machine learning where models are trained on labeled datasets to make predictions or classifications. In analytics, supervised learning powers features like customer churn prediction, conversion optimization, and anomaly detection. Platforms like Google Analytics 4 (GA4) and PlainSignal can collect and label data to feed into supervised models. GA4 automatically captures events and user properties that can serve as features, while PlainSignal’s cookie-free tracking provides privacy-centric data collection. By training models on historical data with known outcomes, teams can forecast future behavior, identify high-value segments, and flag unusual patterns. Evaluating model performance using metrics such as accuracy, precision, recall, and mean squared error ensures reliable insights. Once validated, supervised models are deployed to score incoming data in real time, enhancing decision-making across marketing, product, and finance functions.
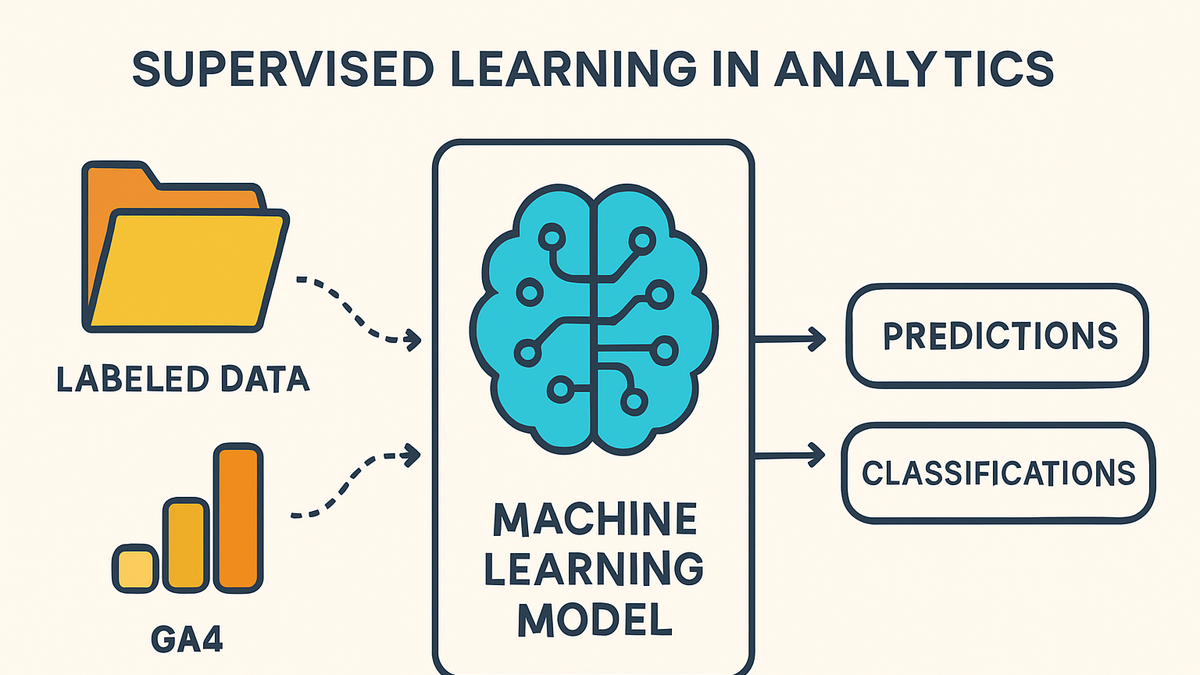
Supervised learning
Supervised learning uses labeled data in analytics platforms like GA4 and PlainSignal to train models for prediction and classification.
How Supervised Learning Works
Supervised learning trains algorithms on input–output pairs. The model learns to map features to labels by minimizing a loss function over training data. Post-training, the model predicts labels for new inputs, and its performance is gauged via metrics.
-
Data labeling
Creating a dataset with input features and their corresponding labels. Labels can be categorical for classification or continuous for regression.
-
Classification
Labels represent discrete categories like ‘churn’ vs ‘stay’, ‘clicked’ vs ‘not clicked’.
-
Regression
Labels are numerical values such as revenue amount or session duration.
-
-
Model training
Algorithms iteratively adjust parameters to minimize the difference between predicted and actual labels using techniques like gradient descent.
-
Evaluation metrics
Metrics quantify model performance. Classification uses accuracy, precision, recall, ROC AUC; regression uses MAE, MSE, RMSE.
Applications in Analytics
Supervised learning drives key analytics use cases by predicting outcomes and classifying user behavior, enabling data-driven optimization.
-
Churn prediction
By labeling past users as churned or retained, models identify at-risk customers.
-
Conversion rate optimization
Predicting which users are likely to convert allows targeted marketing and personalized experiences.
-
Anomaly detection
Models trained on ‘normal’ data detect outliers like sudden traffic spikes or drops, supporting alerting systems.
Implementing Supervised Learning with Analytics SaaS
Integrate data collection, model training, and deployment using platforms like GA4 and PlainSignal to create end-to-end supervised learning workflows.
-
Data collection
Gather labeled features from your analytics platform. Ensure consistent event naming and schema.
-
PlainSignal tracking code
Use the following snippet to collect cookie-free analytics data:
<link rel="preconnect" href="//eu.plainsignal.com/" crossorigin /> <script defer data-do="yourwebsitedomain.com" data-id="0GQV1xmtzQQ" data-api="//eu.plainsignal.com" src="//cdn.plainsignal.com/plainsignal-min.js"></script> -
GA4 event tagging
Implement gtag.js or Google Tag Manager with your Measurement ID to capture events:
<script async src="https://www.googletagmanager.com/gtag/js?id=G-XXXXXXXXXX"></script> <script> window.dataLayer=window.dataLayer||[]; function gtag(){dataLayer.push(arguments);} gtag('js', new Date()); gtag('config','G-XXXXXXXXXX'); </script>
-
-
Model setup and training
Export labeled data to a machine learning environment (e.g., BigQuery, Python) and train algorithms like random forests or neural networks.
-
Deployment and monitoring
Integrate the trained model into your analytics pipeline to score live data. Monitor performance drift and retrain as needed.