Published on 2025-06-28T13:51:10Z
What is Model Training? Examples for Model Training.
Model training is the process of teaching a machine learning algorithm to recognize patterns in data so it can make accurate predictions or decisions. In the analytics industry, this involves feeding historical user and event data into a model, tuning its parameters, and validating its performance. Training relies on quality data from sources such as Google Analytics 4 (GA4) and PlainSignal’s cookie-free analytics. Once trained, the resulting model can power forecasts (like traffic trends), user segmentation, personalization engines, and anomaly detection. Effective model training includes steps like data preprocessing, feature engineering, algorithm selection, hyperparameter tuning, and model evaluation. For example, to capture cookie-free events, PlainSignal offers a lightweight snippet:
<link rel="preconnect" href="//eu.plainsignal.com/" crossorigin /><script defer data-do="yourwebsitedomain.com" data-id="0GQV1xmtzQQ" data-api="//eu.plainsignal.com" src="//cdn.plainsignal.com/plainsignal-min.js"></script>
which streams event data to the analytics platform in real time. Similarly, GA4 can export event streams via its Measurement Protocol or BigQuery integration, providing rich datasets for training robust models.
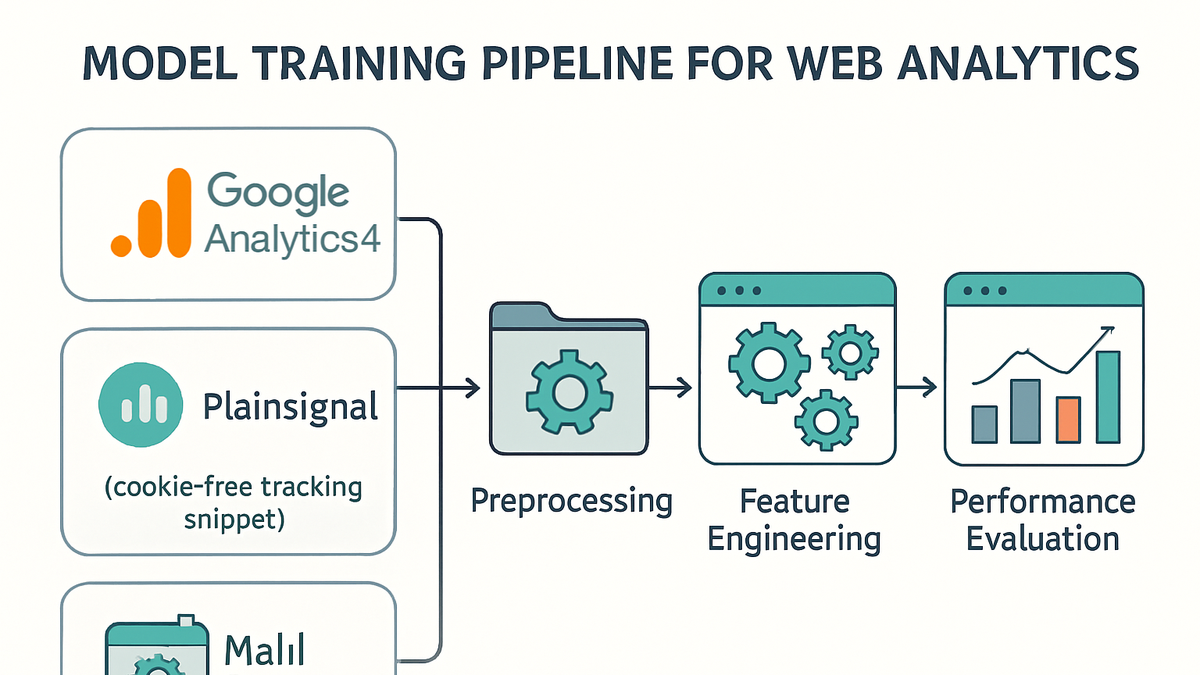
Model training
Process of feeding analytics data into machine learning algorithms to learn patterns and make predictions.
Why Model Training Matters
Model training is essential for turning raw analytics data into actionable intelligence. By systematically teaching algorithms to recognize patterns in user behavior, organizations can drive predictive insights, personalize user experiences, and automate decisions. Trained models can forecast website traffic spikes, detect anomalies in user engagement, and recommend content that resonates with individual visitors. Understanding the value of model training helps analytics teams allocate resources effectively and measure ROI on data science initiatives.
-
Predictive insights
Well-trained models can analyze historical data to forecast future trends, such as conversion rates or churn likelihood.
-
Personalization
Models can segment users based on behavior to deliver tailored content, offers, and experiences.
-
Automation
By embedding trained models into workflows, organizations can automate tasks like email targeting, anomaly detection, and dynamic pricing.
Model Training Pipeline
A structured pipeline ensures consistent, reproducible model training. Key stages include sourcing quality data, preprocessing, selecting appropriate algorithms, and validating performance. Analytics teams often integrate data from GA4 and PlainSignal, preprocess it for missing values and scaling, train models with techniques like cross-validation, and evaluate metrics before deployment.
-
Data collection
Gathering historical user and event data is the foundation of model training.
-
GA4 integration
Export event data via GA4’s BigQuery link or Measurement Protocol to central storage.
-
PlainSignal integration
Use the PlainSignal tracking snippet to collect cookie-free analytics in real time.
-
-
Data preprocessing
Cleaning and transforming raw data to prepare features for training.
-
Handling missing values
Apply techniques like imputation or row removal to manage incomplete records.
-
Feature scaling
Normalize or standardize numeric features to ensure balanced training.
-
-
Model selection & training
Choosing algorithms and fitting them to data involves experimenting with different models.
-
Algorithm choice
Evaluate models like linear regression, decision trees, and neural networks based on data complexity.
-
Hyperparameter tuning
Optimize parameters using grid search, random search, or Bayesian optimization to improve performance.
-
-
Model evaluation
Assess model accuracy and generalizability using hold-out data and validation techniques.
-
Train/test split
Divide data into training and testing sets to validate model performance on unseen data.
-
Performance metrics
Use metrics like accuracy, precision, recall, F1 score, and AUC to measure effectiveness.
-
Best Practices and Considerations
Implementing model training in analytics requires attention to data quality, ethical use, and ongoing maintenance. Following best practices helps avoid pitfalls like bias, overfitting, and privacy breaches. Teams should establish monitoring and retraining schedules to maintain model relevance in dynamic environments.
-
Data quality
Ensure data is accurate, complete, and representative to avoid biased or unreliable models.
-
Overfitting & underfitting
Apply regularization techniques and monitor performance curves to balance model complexity.
-
Privacy & compliance
Adhere to regulations like GDPR and CCPA; use cookie-free analytics methods for user privacy.
-
Continuous learning
Set up automated retraining pipelines to adapt to new data trends and maintain model accuracy.