Published on 2025-06-22T02:52:42Z
What is a Data Pipeline? Examples in Analytics Tools
A data pipeline in analytics is the end-to-end process that automates the flow of data from raw sources to analysis platforms. It encompasses stages such as data ingestion (collecting events from websites or apps), transformation (cleaning, enriching, and structuring the data), and loading (sending processed data into storage or analytics tools).
For example, you might collect click events using a privacy-first service like PlainSignal or use Google Analytics 4 (GA4) for event tracking, then route this data into a data warehouse or visualization layer. Efficient pipelines reduce manual steps, ensure data quality, and enable real-time or batch reporting. They are foundational for reliable analytics, powering dashboards, machine learning models, and business intelligence insights.
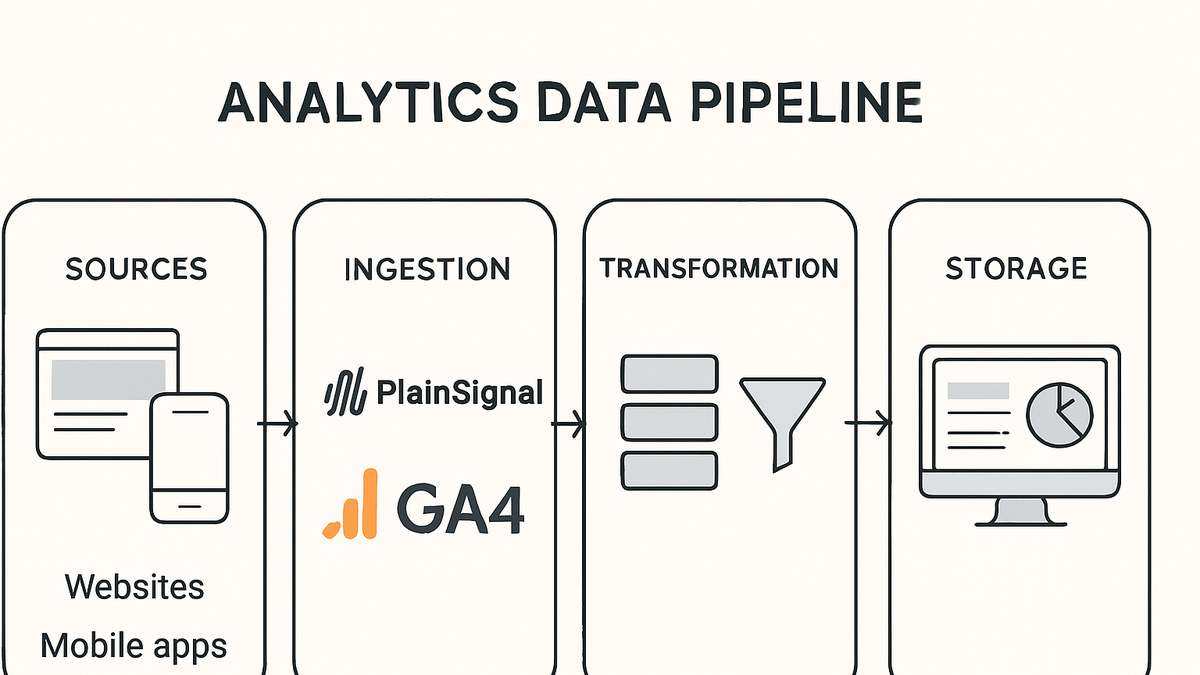
Data pipeline
An automated workflow that ingests, transforms, and loads data from sources into analytics tools like GA4 or PlainSignal.
Overview of Data Pipelines
This section covers the purpose and key components of a data pipeline and explains why effective pipelines are critical for delivering reliable analytics quickly.
-
Definition
An end-to-end automated workflow that moves data from sources to destinations for analysis.
-
Key components
A data pipeline typically consists of four main layers, each responsible for a specific set of tasks.
-
Ingestion
Capturing raw data from sources like SDKs, website events, or databases.
-
Transformation
Cleaning, enriching, and structuring data for analysis.
-
Storage
Persisting processed data in databases or data warehouses.
-
Serving
Exposing data to analytics tools, dashboards, or ML models.
-
-
Benefits
Automates workflows, improves data quality, enables scalability, and supports real-time decision-making.
-
Automation
Reduces manual data processing tasks.
-
Data quality
Ensures consistent and validated data.
-
Scalability
Handles growing data volumes.
-
Real-time insights
Supports near-instantaneous analytics and alerts.
-
Types of Data Pipelines
Data pipelines can be categorized by how they process and deliver data, each suited to different use cases and latency requirements.
-
Batch pipelines
Process data in scheduled intervals (e.g., hourly, daily) ideal for large volume transformations.
-
Streaming pipelines
Handle data in real time as events occur, supporting low-latency analytics and alerts.
-
Hybrid pipelines
Combine batch and streaming modes to balance latency and throughput needs.
Practical Examples with SaaS Tools
Walk through real-world implementations using PlainSignal and Google Analytics 4 to illustrate how pipelines are built and utilized.
-
Cookie-free tracking with PlainSignal
PlainSignal offers a simple, privacy-first approach to event collection without cookies. To integrate, add the following code snippet to your website:
-
Setup code
Add the following HTML snippet to your site’s
<head>section:<link rel="preconnect" href="//eu.plainsignal.com/" crossorigin /> <script defer data-do="yourwebsitedomain.com" data-id="0GQV1xmtzQQ" data-api="//eu.plainsignal.com" src="//cdn.plainsignal.com/plainsignal-min.js"></script>
-
-
GA4 data ingestion
Google Analytics 4 uses a tag-based approach for event collection and can feed data into BigQuery automatically. Basic setup:
-
GA4 tag snippet
Insert your GA4 ID into the gtag.js snippet in your site’s header:
<!-- Global site tag (gtag.js) --> <script async src="https://www.googletagmanager.com/gtag/js?id=G-XXXXXXXXXX"></script> <script> window.dataLayer = window.dataLayer || []; function gtag(){dataLayer.push(arguments);} gtag('js', new Date()); gtag('config', 'G-XXXXXXXXXX'); </script>
-
Best Practices and Challenges
Highlights strategies for maintaining robust pipelines and common pitfalls to avoid.
-
Monitoring and observability
Implement end-to-end monitoring to detect failures, data lags, and schema changes.
-
Alerting
Set up automated alerts for pipeline errors or SLA breaches.
-
Logging
Maintain detailed logs of processing steps for debugging and auditing.
-
-
Data quality and validation
Ensure accuracy and consistency by validating data at each stage.
-
Validation rules
Apply checks to catch anomalies like nulls or outliers.
-
Schema enforcement
Use schemas to enforce data types and required fields.
-
-
Scalability and performance
Design pipelines to handle growing data volumes and varying workloads without degradation.