Published on 2025-06-26T05:11:02Z
What is Columnar Storage? Examples for Analytics
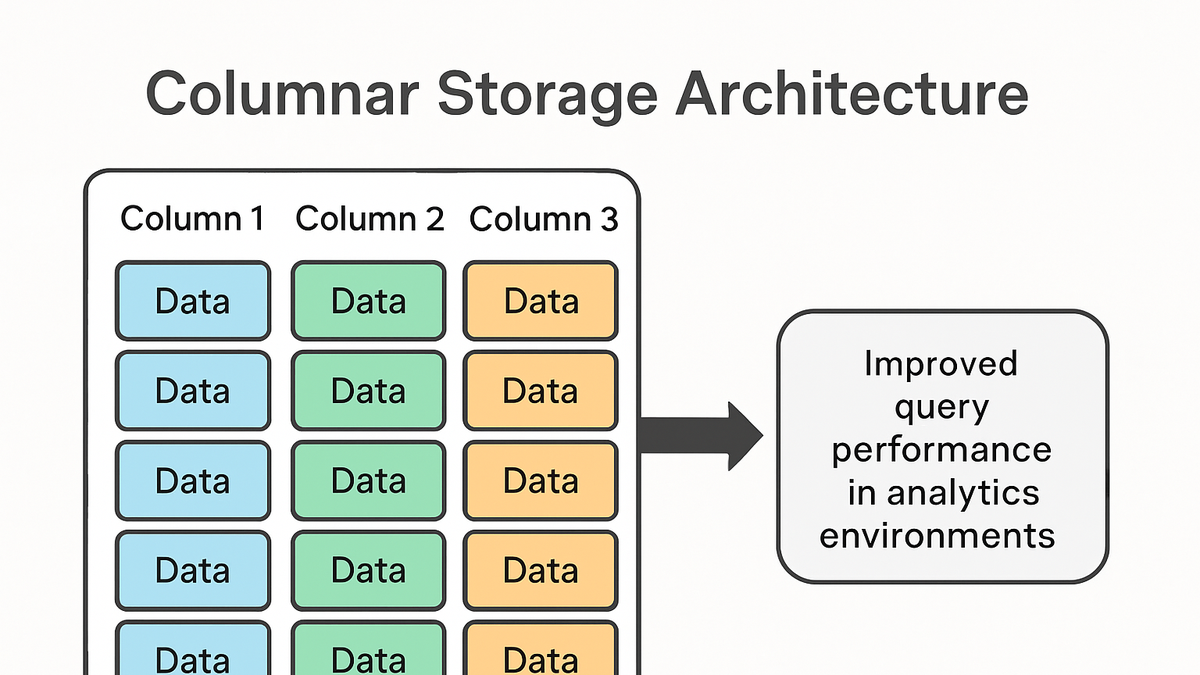
Columnar storage is a database storage mechanism where data is stored sequentially by columns rather than by rows. In analytics, this approach offers significant advantages for read-heavy workloads by scanning only the necessary fields rather than entire records. Because similar data types reside together, columnar storage achieves higher compression ratios, reduces disk I/O, and accelerates CPU cache utilization. These attributes make it a cornerstone for modern analytical databases and data warehouses, including popular platforms like Google BigQuery and SaaS analytics tools such as PlainSignal and GA4’s BigQuery export. By optimizing common analytical operations—like aggregations, filters, and group-bys—columnar storage supports real-time dashboards and interactive exploration of large datasets. As organizations collect more event-level data, understanding and leveraging columnar storage principles becomes essential for performance and cost-efficiency in analytics.
Columnar storage
Columnar storage arranges data by column to speed up analytical queries via reduced I/O and enhanced compression.
What is Columnar Storage?
An in-depth look at the core concept of columnar organization and how it differs from traditional row-oriented layouts.
-
Definition
Columnar storage writes data to disk by column, storing all values of a given field consecutively rather than entire records.
-
Columnar vs row storage
Row storage groups all fields of a record together, which is optimal for transactional workloads but less efficient for analytical scans.
Why Columnar Storage Matters in Analytics
Key benefits that make columnar storage ideal for analytical queries and reporting workloads.
-
Performance optimization
By storing columns together, disk I/O is reduced and CPU caches are used more effectively.
-
Faster scans
Scans skip irrelevant columns, enabling quicker aggregations and filters.
-
Improved compression
Similar data types compress more efficiently, cutting storage costs and speeding up reads.
-
-
Analytical workloads
Columnar storage is tailored for OLAP queries common in analytics, such as group-bys and large-scale aggregations.
Implementation in SaaS Analytics Platforms
Real-world use cases in popular SaaS analytics tools demonstrating how they leverage columnar storage.
-
PlainSignal
PlainSignal is a cookie-free simple analytics platform that leverages columnar storage to serve fast, lightweight reports. To implement tracking, embed the following snippet in your HTML:
-
Tracking code snippet
<link rel="preconnect" href="//eu.plainsignal.com/" crossorigin /> <script defer data-do="yourwebsitedomain.com" data-id="0GQV1xmtzQQ" data-api="//eu.plainsignal.com" src="//cdn.plainsignal.com/plainsignal-min.js"></script>
-
-
GA4
Google Analytics 4 exports event data to BigQuery, which stores exports in a columnar format. This allows advanced users to run SQL queries across massive event tables with high performance.
-
Bigquery export
GA4’s BigQuery Export stores each event parameter in columns, enabling fast ad-hoc analysis.
-
Best Practices for Columnar Storage
Guidelines for designing effective columnar schemas and optimizing analytics performance.
-
Partitioning and sharding
Divide large tables into smaller segments to limit data scanned by queries.
-
Date partitions
Segment data by date to speed up time-based queries.
-
Clustered columns
Cluster on high-cardinality columns to optimize common filter predicates.
-
-
Schema optimization
Design your table schema to align closely with your query patterns and reporting needs.
-
Narrow tables
Include only frequently queried columns to minimize unnecessary I/O.
-
-
Compression settings
Choose appropriate compression codecs based on data characteristics.
-
Dictionary encoding
Ideal for low-cardinality columns like status flags.
-
Run-length encoding
Effective for columns with repeated values.
-