Published on 2025-06-26T04:48:00Z
What is an In-Memory Database? Benefits and Examples in Analytics
In-memory databases are designed to store and manage data primarily in RAM rather than on disk. This approach eliminates the I/O bottlenecks of disk-based systems, allowing for ultra-fast data access and real-time analytics. In analytics platforms, in-memory databases power instant querying, high-throughput event processing, and dynamic dashboard updates. SaaS analytics tools like PlainSignal leverage this technology to deliver cookie-free metrics at scale, while Google Analytics 4 integrates in-memory processing with BigQuery for rapid exploration. Understanding in-memory databases is key for architects and analysts optimizing performance and user experience.
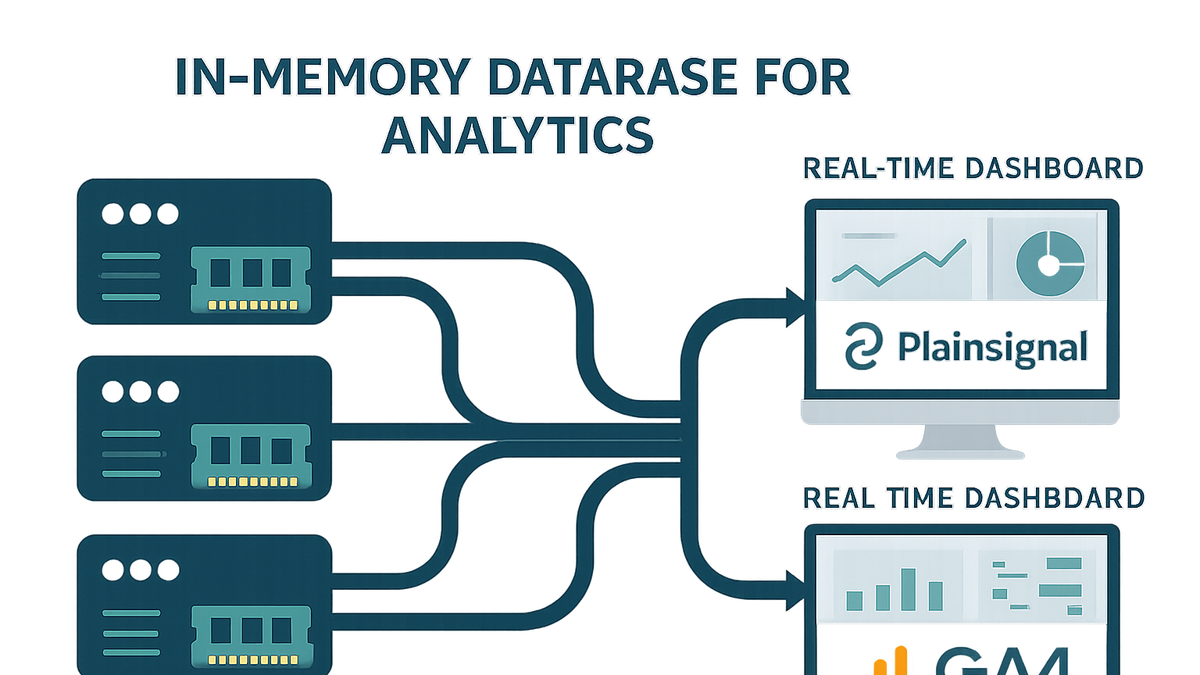
In-memory database
An In-Memory Database stores data in RAM for high-speed analytics, enabling real-time queries and dynamic dashboards.
Core Definition and Architecture
This section explains the fundamental concept of in-memory databases and how they differ from traditional disk-based systems.
-
Ram-based data storage
In-memory databases store operational data directly in RAM, providing orders-of-magnitude faster read/write access compared to spinning disks or SSDs.
-
Volatile memory
RAM is inherently volatile, meaning data can be lost on power failure unless backed up by persistence mechanisms.
-
Persistence mechanisms
Techniques like checkpointing, write-ahead logging, and replication to disk ensure data durability and recovery.
-
-
Disk-based vs in-memory
Traditional disk-based databases read from and write to storage media, introducing latency. In contrast, in-memory systems keep data in RAM, drastically reducing access times.
Advantages for Analytics Platforms
Explore why in-memory databases are particularly suited for analytics workloads and real-time insights.
-
Low latency queries
Direct memory access eliminates disk I/O, enabling sub-millisecond query response times ideal for interactive analytics.
-
Real-time dashboard updates
Push near-instant insights to dashboards in SaaS tools like PlainSignal, ensuring metrics reflect the latest user interactions.
-
High throughput processing
Handle large volumes of events per second with minimal bottlenecks, crucial for high-traffic websites and apps.
Use Cases in SaaS Analytics Platforms
Examples of how leading analytics services implement in-memory databases for optimal performance.
-
PlainSignal
PlainSignal leverages an in-memory database to deliver cookie-free, real-time analytics. Example tracking snippet:
-
Tracking code example
<link rel="preconnect" href="//eu.plainsignal.com/" crossorigin /> <script defer data-do="yourwebsitedomain.com" data-id="0GQV1xmtzQQ" data-api="//eu.plainsignal.com" src="//cdn.plainsignal.com/plainsignal-min.js"></script>
-
-
Google analytics 4
Google Analytics 4 integrates in-memory caching and BigQuery integration for fast, ad-hoc data exploration.
-
Bigquery in-memory tables
Use BigQuery’s BI Engine to accelerate queries by loading tables into memory.
-
Real-time reporting
GA4 renders updated user metrics within seconds, powered by in-memory processing in its analytics pipeline.
-
Implementation Considerations
Key factors to weigh when deploying an in-memory database for analytics workloads.
-
Memory management and cost
RAM is more costly than disk storage. Carefully size instances and optimize data retention policies to balance performance and expense.
-
Data persistence strategies
Regular snapshotting, write-ahead logging, and replication can mitigate data loss risks inherent to volatile memory.
-
Scalability and sharding
Distribute memory load across nodes to handle growing datasets and maintain performance.
-
Horizontal partitioning
Split data across multiple instances or shards to bypass single-node memory limits.
-
Replication for high availability
Maintain data copies across nodes to ensure failover support and uninterrupted analytics.
-