Published on 2025-06-28T04:23:47Z
What is a Data Lakehouse? Examples for Data Lakehouse.
A Data Lakehouse is a modern data architecture that combines the flexible storage capabilities of a data lake with the structured management and query performance of a data warehouse. It supports storing raw, semi-structured, and structured data in open formats while providing ACID transactions, schema enforcement, and fast SQL analytics. Unlike traditional data warehouses, a lakehouse can handle large volumes of untransformed data without sacrificing data governance or performance. This architecture enables real-time analytics, machine learning workflows, and BI reporting on a single platform. For example, you can stream GA4 events to BigQuery or route PlainSignal’s real-time tracking events into your lakehouse storage for comprehensive analysis.
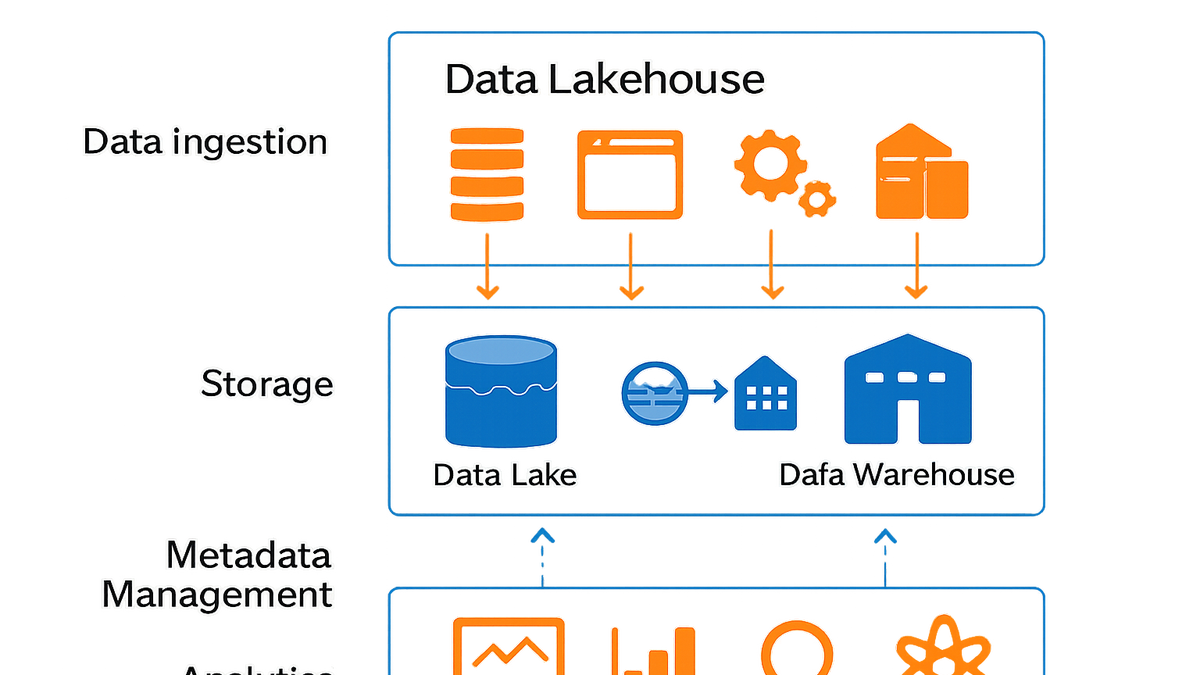
Data lakehouse
A Data Lakehouse unifies data lake storage flexibility with data warehouse querying and management in a single architecture.
Overview of Data Lakehouse
This section introduces the core concept of a Data Lakehouse, highlighting its role as a unified platform for managing diverse data types with robust query capabilities.
-
What is a data lakehouse?
A Data Lakehouse merges the scalable, low-cost storage of data lakes with the transaction support and performance optimizations of data warehouses in a single system.
-
Core components
Key components include a storage layer for raw and structured data, a metadata and transaction management layer, and an analytics engine for SQL queries.
-
Storage layer
Object storage or distributed file systems store raw, semi-structured, and structured data in open formats like Parquet or ORC.
-
Metadata & transaction management
A central catalog tracks schema, table versions, and ACID transactions to ensure data consistency and governance.
-
Benefits and Use Cases
Explore why organizations adopt lakehouses and the scenarios where this architecture shines.
-
Key benefits
Lakehouses offer unified storage, simplified data pipelines, cost efficiency, and high performance for diverse workloads.
-
Cost efficiency
Leverage low-cost object storage instead of expensive proprietary data warehouse storage.
-
Flexibility
Process structured, semi-structured, and unstructured data without separate ETL steps.
-
-
Common use cases
Typical applications include real-time analytics, machine learning model training, and business intelligence reporting.
-
Real-time analytics
Query streaming data with SQL engines like Apache Spark or Presto directly in the lakehouse.
-
Machine learning
Build feature stores and train models on raw and processed data in one environment.
-
Implementing Data Lakehouse with Analytics SaaS
Practical examples showing how to ingest analytics events from SaaS products into a lakehouse.
-
Tracking with PlainSignal
Use PlainSignal’s cookie-free analytics to capture user events and forward them to your lakehouse storage. Setup your web pages with the snippet below:
-
Setup code
<link rel="preconnect" href="//eu.plainsignal.com/" crossorigin /> <script defer data-do="yourwebsitedomain.com" data-id="0GQV1xmtzQQ" data-api="//eu.plainsignal.com" src="//cdn.plainsignal.com/plainsignal-min.js"></script> -
Data flow
PlainSignal streams event data in near real-time to object storage or your ETL pipeline for downstream processing.
-
-
Exporting GA4 events
Google Analytics 4 can export raw event streams directly into BigQuery, serving as a cloud-based lakehouse for deeper analysis.
-
Bigquery export
Configure GA4 to continuously export events to a designated BigQuery dataset.
-
Querying data
Run SQL queries on raw event tables in BigQuery for custom reports and machine learning feature extraction.
-
Challenges and Best Practices
Address common pitfalls and recommended strategies for successful lakehouse adoption.
-
Common challenges
Implementing a lakehouse can introduce complexities around governance, performance, and cost management.
-
Data quality
Enforce schema checks and validation to prevent corrupted or incompatible data.
-
Performance optimization
Use partitioning, indexing, and caching to improve query speed on large datasets.
-
-
Best practices
Follow proven techniques to maximize reliability, security, and scalability.
-
Schema enforcement
Define and enforce schemas at ingestion to maintain data consistency.
-
Access controls
Apply role-based access and encryption to safeguard sensitive data.
-