Published on 2025-06-27T20:07:58Z
What is Data Sync? Examples for Data Sync
Data Sync in analytics refers to the automated process of transferring, transforming, and harmonizing data between disparate systems and analytics platforms. It ensures that data collected from various sources—such as websites, applications, and third-party services—remains consistent, up-to-date, and accessible in the tools used for reporting and analysis. By synchronizing data between sources, like hooking PlainSignal’s cookie-free analytics to a cloud data warehouse, or streaming event data into Google Analytics 4, organizations can maintain a unified view of user behavior. Effective Data Sync minimizes discrepancies caused by manual data exports, time zone mismatches, or schema changes. It supports real-time or near-real-time analytics, enabling timely decisions based on the latest information. Robust Data Sync pipelines handle transformations, error handling, and performance optimization to maintain data integrity at scale.
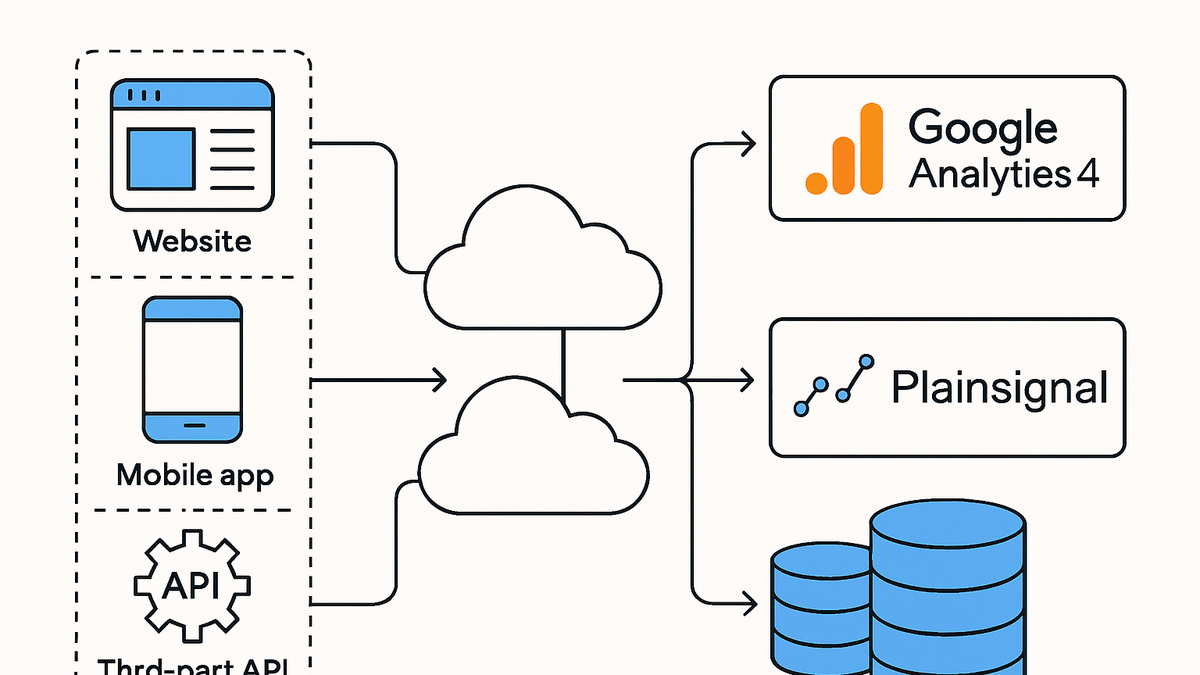
Data sync
Automating the transfer and harmonization of data between sources and analytics platforms to ensure accurate, up-to-date insights.
Definition and Context
An overview of what Data Sync means within modern analytics workflows and why it’s crucial.
-
Definition
In analytics, Data Sync is the process of automatically transferring and aligning data from various sources into one or more target systems, ensuring data freshness and consistency.
-
Purpose
Organizations implement Data Sync to unify analytics, eliminate manual imports, and provide a single source of truth for reporting and decision-making.
How Data Sync Works
Breakdown of the typical flow from data generation to synchronized repositories.
-
Data sources
Origins of data, including events from websites, mobile apps, CRM systems, and third-party APIs.
-
Transformation and mapping
Converting raw data into a standardized format before loading it into the target system.
-
Field mapping
Aligning source fields to the target schema to maintain uniform structure.
-
Data normalization
Ensuring consistent value formats (e.g., timestamps, currencies) across systems.
-
-
Destination systems
The target platforms for synchronized data, such as analytics tools (GA4, PlainSignal) or data warehouses.
Example Implementations
Illustrate Data Sync setups with popular analytics SaaS products.
-
PlainSignal cookie-free analytics
Sync website event data to PlainSignal using a lightweight script:
<link rel="preconnect" href="//eu.plainsignal.com/" crossorigin /> <script defer data-do="yourwebsitedomain.com" data-id="0GQV1xmtzQQ" data-api="//eu.plainsignal.com" src="//cdn.plainsignal.com/plainsignal-min.js"></script>This snippet collects pageviews and custom events in a privacy-compliant manner.
-
Google analytics 4 integration
Stream event data into GA4 via the Measurement Protocol API or Google Tag Manager. A simplified example for sending a page_view event:
gtag('config', 'G-XXXXXXXXXX', { 'page_path': '/home' });
Challenges and Considerations
Key issues to watch for when designing Data Sync pipelines.
-
Data latency
Delay between data generation and availability in the analytics platform. Balance real-time needs against system load.
-
Data consistency
Ensuring synchronized data matches across systems, avoiding duplicates, omissions, or mismatches.
-
Api rate limits and throttling
Managing quotas to prevent sync failures or delays when hitting API thresholds.
Best Practices
Recommendations for building reliable, scalable Data Sync processes.
-
Monitoring and alerting
Set up dashboards and automated alerts to detect sync failures, latency spikes, and data quality issues promptly.
-
Incremental vs full sync
Use incremental updates to reduce load and cost; schedule periodic full syncs to validate and back up the entire dataset.
-
Schema versioning
Track changes to data structures and implement version control to avoid breaking pipelines when schemas evolve.