Published on 2025-06-26T04:32:25Z
What is Data Warehousing? Examples and Use Cases
Data warehousing is the practice of collecting, storing, and managing data from multiple sources into a centralized repository optimized for reporting and analysis. A data warehouse serves as a single source of truth, enabling organizations to run complex queries across historical and real-time data. Unlike operational databases designed for transaction processing, data warehouses are structured for high-performance analytics and support large-scale data transformations. Modern data warehouses leverage cloud platforms like Google BigQuery, Amazon Redshift, and Snowflake to scale storage and compute independently. By integrating data from web analytics tools such as GA4 and PlainSignal, businesses can combine user behavior metrics with transactional and CRM data to uncover deeper insights and drive data-driven decision-making.
Data warehousing strategies often involve ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) processes to ensure data quality and consistency. They also incorporate metadata management and OLAP engines to support multi-dimensional analysis and reporting capabilities.
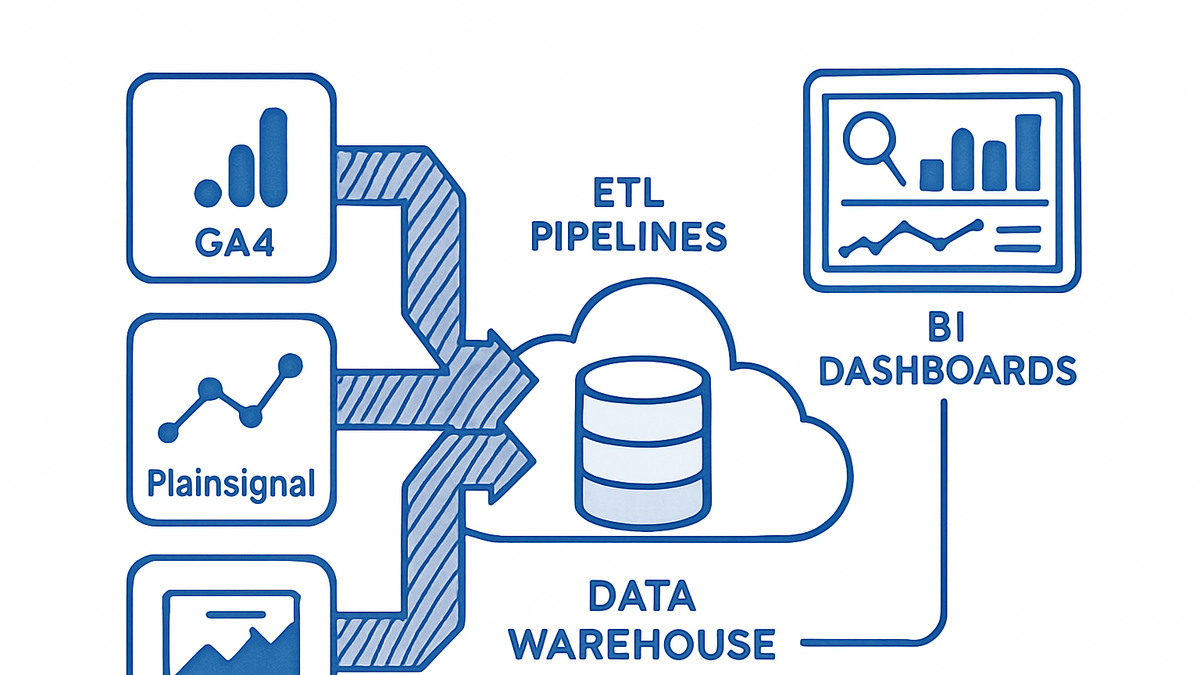
Data warehousing
Centralized repository for collecting and structuring data from various sources to support high-performance analytics and reporting.
Why Data Warehousing Matters
This section explains the core reasons organizations invest in data warehousing, including unifying data sources, improving query performance, and enabling advanced analytics.
-
Single source of truth
By consolidating data from multiple systems into one repository, a data warehouse ensures consistency and avoids discrepancies across reports.
-
Improved query performance
Data warehouses are optimized for read-heavy workloads, using columnar storage and indexing to accelerate complex analytical queries.
-
Historical analysis
Storing time-stamped data allows analysts to track trends and patterns over long periods, essential for forecasting and strategic planning.
-
Scalability
Cloud-based data warehouses can scale storage and compute resources independently, accommodating growing data volumes and concurrent users.
Key Components of a Data Warehouse
Learn about the fundamental building blocks of a data warehouse, from data ingestion pipelines to analytical engines.
-
Etl/elt processes
ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) workflows are responsible for moving data from source systems into the warehouse, cleaning and structuring it.
-
Extract
Pull data from various sources such as databases, APIs, and log files.
-
Transform
Cleanse, enrich, and convert data into a consistent format.
-
Load
Write transformed data into the warehouse for analysis.
-
-
Storage layer
The storage component uses optimized formats (e.g., columnar storage, partitioning, compression) to store large volumes of data efficiently.
-
Metadata and data catalog
Metadata repositories track data definitions, schemas, lineage, and ownership to simplify discovery and governance.
-
Olap engine
Online Analytical Processing (OLAP) engines support multi-dimensional queries, allowing rapid aggregation and drill-down of data.
Data Warehouse Architectures
Explore different architectural patterns for deploying data warehouses, from on-premises to modern cloud-native designs.
-
On-premises vs. cloud
On-premises solutions offer control over infrastructure but require significant maintenance, whereas cloud services deliver flexibility and managed scaling.
-
Hub-and-spoke
A central warehouse collects data, and downstream data marts serve specialized departmental needs, balancing central governance with localized performance.
-
Federated architecture
Data remains in source systems and is queried on demand, reducing data movement but often at the cost of query performance.
-
Modern lakehouse
Combines features of data lakes and warehouses, leveraging open formats like Parquet and Delta Lake to support both raw and structured data.
Implementation Process
Step-by-step guide to planning, designing, and building a data warehouse tailored to your organization’s needs.
-
Requirements gathering
Identify key data sources, user personas, reporting requirements, and performance SLAs to shape the warehouse design.
-
Schema design
Decide on a data model, such as star or snowflake schema, that organizes facts and dimensions for efficient querying.
-
Star schema
Central fact tables linked to denormalized dimension tables for straightforward queries.
-
Snowflake schema
Normalized dimensions split into related tables to reduce redundancy.
-
-
Tool selection
Choose a data warehouse platform (e.g., BigQuery, Snowflake, Redshift) and ETL/ELT tools (e.g., Fivetran, Airbyte) that fit your scale and budget.
-
Data ingestion and validation
Set up pipelines to load data, implement quality checks, and validate schemas to ensure data integrity.
-
Testing and optimization
Perform query benchmarks, optimize indexes and partitions, and refine transformations based on cost and performance.
Best Practices and Considerations
Key strategies to ensure your data warehouse remains secure, cost-effective, and high-performing.
-
Data governance and security
Implement role-based access control, encryption at rest and in transit, and auditing to protect sensitive information.
-
Access control
Define roles and permissions to restrict data to authorized users.
-
Encryption
Use encryption across storage and network layers to secure data.
-
-
Performance optimization
Use partitioning, clustering, and caching strategies to speed up queries and lower compute costs.
-
Partitioning
Divide large tables into segments based on keys (e.g., date) for targeted scans.
-
Indexing
Create indexes on frequently queried columns to reduce query latency.
-
Compression
Apply compression algorithms to reduce storage footprint and I/O.
-
-
Cost management
Monitor storage and compute usage, set budgets, and leverage auto-scaling features to optimize spend.
-
Storage costs
Archive cold data and choose appropriate storage tiers.
-
Compute costs
Use reserved capacity or on-demand instances based on workload patterns.
-
Auto-scaling
Enable automatic resource adjustments to balance performance and cost.
-
-
Monitoring and alerting
Establish metrics and alerts for data freshness, pipeline failures, and query performance to maintain reliability.
-
Pipeline monitoring
Track ETL job statuses and failures.
-
Query metrics
Monitor long-running queries and resource usage.
-
Example Integrations with Analytics SaaS Tools
Demonstrates how to route analytics data from SaaS platforms like PlainSignal and GA4 into your data warehouse for unified reporting.
-
PlainSignal integration
Implement PlainSignal’s cookie-free tracking and export event data to your warehouse.
-
Tracking code
<link rel="preconnect" href="//eu.plainsignal.com/" crossorigin /> <script defer data-do="yourwebsitedomain.com" data-id="0GQV1xmtzQQ" data-api="//eu.plainsignal.com" src="//cdn.plainsignal.com/plainsignal-min.js"></script> -
Data export
Use PlainSignal’s API or a connector (e.g., Fivetran) to stream event data into your warehouse.
-
Use case
Combine PlainSignal metrics with sales data to analyze conversion funnels without relying on cookies.
-
-
Google analytics 4 (GA4) integration
Stream GA4 data directly into BigQuery for in-depth user behavior analysis.
-
Bigquery export
Enable the BigQuery linking in GA4 to automatically export event data.
-
Schema overview
GA4 exports include events, user_properties, and traffic_source tables.
-
Querying data
Use SQL to query event parameters and join with other data sources for comprehensive insights.
-