Published on 2025-06-28T07:42:19Z
What is Schema-on-Read? Examples for Analytics
Schema-on-read is a data architecture pattern where the schema is applied at the time of data retrieval rather than at ingestion. In analytics, this approach allows organizations to ingest raw event streams, logs, and semi-structured data into a centralized storage—such as a data lake—and then impose a schema when querying the data for insights.
Unlike schema-on-write, which enforces a predefined structure before data is stored, schema-on-read offers flexibility to adapt to evolving data sources without costly upfront modeling. When a query is executed, the analytics engine interprets the raw data on-the-fly, dynamically mapping fields and types according to the analytical requirements. This enables agile experimentation, supports diverse data formats (JSON, XML, CSV), and reduces the time between data collection and actionable insights.
Tools like Google Analytics 4 (GA4) leverage schema-on-read via BigQuery exports, while privacy-focused solutions such as PlainSignal (cookie-free analytics) process raw event data dynamically. However, teams must address performance overhead, metadata management, and governance to fully realize the benefits of schema-on-read.
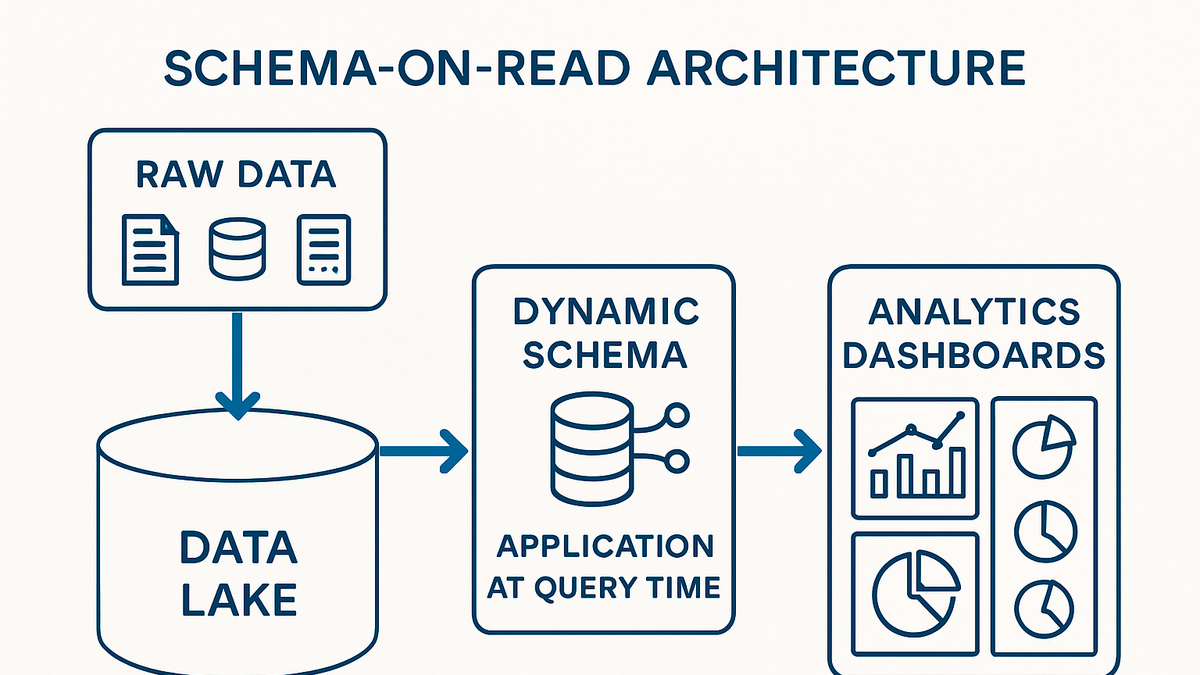
Schema-on-read
Flexible analytics model applying schema at query time for agile, scalable data insights.
Overview of Schema-on-Read
This section introduces the concept of schema-on-read, explaining how it differs from traditional data modeling and why it’s relevant in modern analytics contexts. It covers the foundational principles and situates schema-on-read within the data architecture landscape.
-
Definition
Schema-on-read is a design pattern where data is ingested in its raw form and the schema is applied only when the data is read or queried. This approach allows data teams to store heterogeneous datasets without upfront transformation.
-
How it works
When a query is executed, the analytics engine parses the raw data, infers or applies the schema, and then returns structured results. This on-the-fly mapping enables late binding and flexible data exploration.
-
Key characteristics
Late binding, support for semi-structured formats (like JSON, XML), and dynamic schema evolution without rigid upfront modeling.
Schema-on-Read vs Schema-on-Write
Contrasting schema-on-read with schema-on-write highlights trade-offs between flexibility and performance. This section explores both paradigms, guiding when to choose each based on use cases and constraints.
-
Schema-on-read
Applies schema at query time, enabling rapid ingestion and adaptation to changing data without upfront modeling. Ideal for exploratory analytics and data lakes.
-
Schema-on-write
Enforces schema before or during data ingestion, storing data in a predefined structure. Common in data warehouses where consistent schema and optimized performance are critical.
-
Comparison
Below are key differences between the two approaches:
-
Ingestion speed
Schema-on-read allows faster ingestion as data is loaded raw. Schema-on-write requires transformation at load time, slowing ingestion.
-
Query performance
Schema-on-write can be optimized for fast querying. Schema-on-read may incur overhead during schema application.
-
Flexibility
Schema-on-read is more adaptable to new data types. Schema-on-write requires schema updates and migrations.
-
Data quality control
Schema-on-write enforces consistency upfront. Schema-on-read shifts quality checks to query time.
-
Benefits and Challenges
This section examines the advantages of schema-on-read for analytics teams and the potential pitfalls that must be managed. Understanding both sides ensures effective adoption.
-
Benefits
Schema-on-read empowers analytics teams to rapidly ingest varied data sources, experiment with new data models, and scale storage cost-effectively.
-
Agility
No upfront schema design accelerates time-to-insight and supports ad-hoc analysis.
-
Cost efficiency
Raw storage in data lakes is often cheaper than pre-transformed warehouses.
-
Data variety
Supports semi-structured and unstructured data formats without complex ETL pipelines.
-
-
Challenges
Despite its flexibility, schema-on-read can introduce performance and governance challenges that teams must address.
-
Performance overhead
Dynamic schema application can slow down complex queries, requiring optimization.
-
Governance complexity
Managing metadata, access controls, and data quality at query time adds operational overhead.
-
Tooling requirements
Requires analytics platforms capable of efficient on-the-fly transformations.
-
Implementing Schema-on-Read in Analytics Platforms
Practical guidance on how to leverage schema-on-read in leading analytics tools, with real examples from PlainSignal and GA4.
-
PlainSignal (cookie-free analytics)
PlainSignal uses schema-on-read to process raw event data without cookies, offering a privacy-friendly analytics solution.
-
Setup example
Add the following tracking code to your site:
<link rel='preconnect' href='//eu.plainsignal.com/' crossorigin /> <script defer data-do='yourwebsitedomain.com' data-id='0GQV1xmtzQQ' data-api='//eu.plainsignal.com' src='//cdn.plainsignal.com/plainsignal-min.js'></script>
-
-
Google analytics 4
GA4 supports schema-on-read when exporting data to BigQuery, where raw event tables can be queried with custom schemas.
-
Bigquery export
Set up daily exports of raw GA4 events to BigQuery, then apply SQL transformations at query time.
-
Flexible reporting
Use SQL functions to dynamically parse nested event parameters without rigid schemas.
-
Best Practices
Key recommendations to maximize the benefits of schema-on-read while mitigating risks.
-
Ensure data quality
Implement automated validation checks and data profiling at query time to catch anomalies.
-
Plan for performance
Use partitioning, clustering, and caching strategies to optimize on-the-fly schema application.
-
Metadata management
Maintain a comprehensive data catalog and clear metadata definitions to support dynamic schema resolution.
-
Naming conventions
Standardize field names and data types across datasets for consistency.
-
Version control
Track schema evolution and maintain versioned metadata to handle changes gracefully.
-